

Welcome Back to the 3rd and the last part of The Fundamentals of Machine Learning. In this blog, we will be covering Instance-Based learning and Model-Based Learning and we will also discuss the main challenges in Machine Learning.
Instance-Based Learning
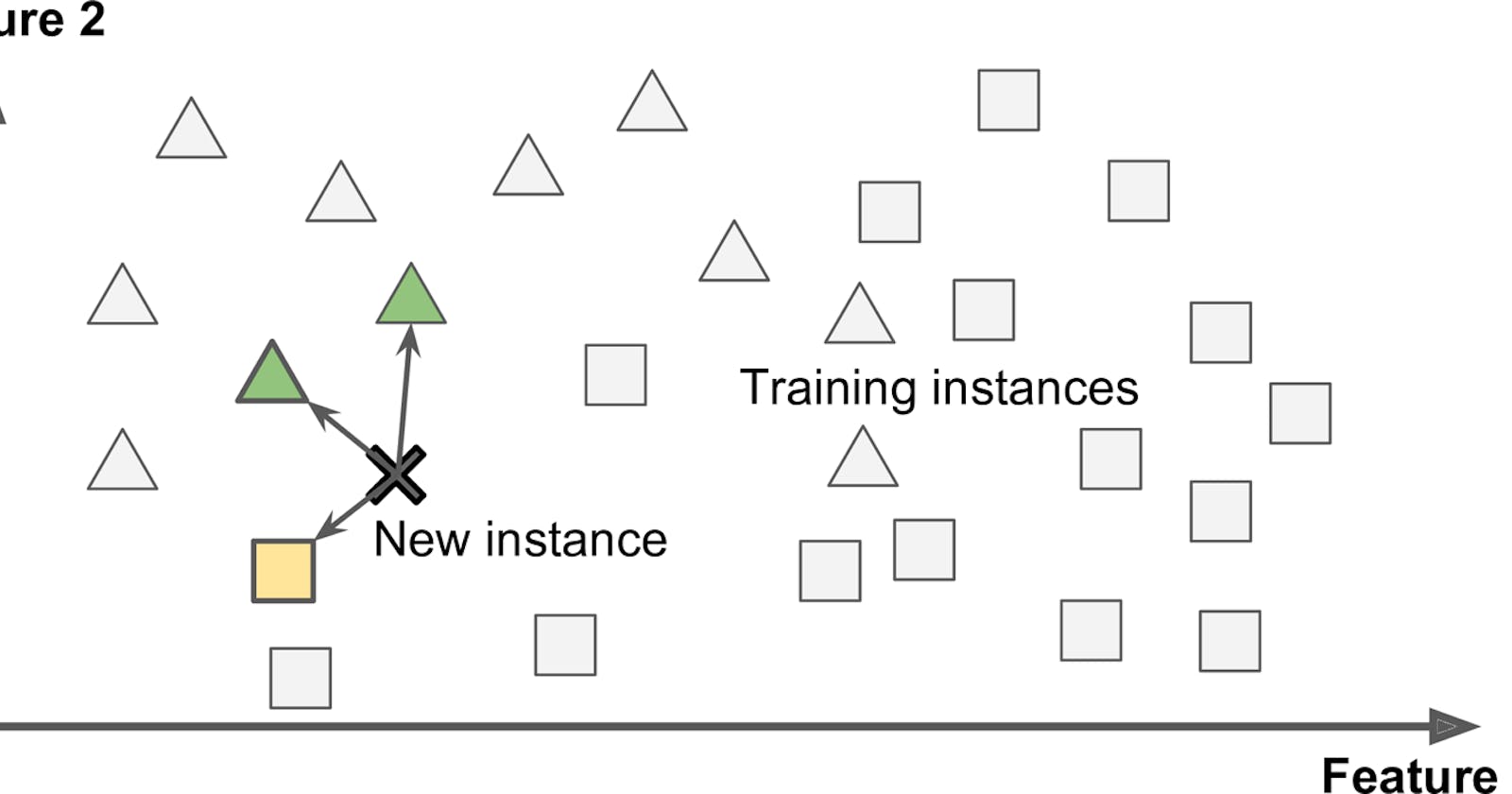
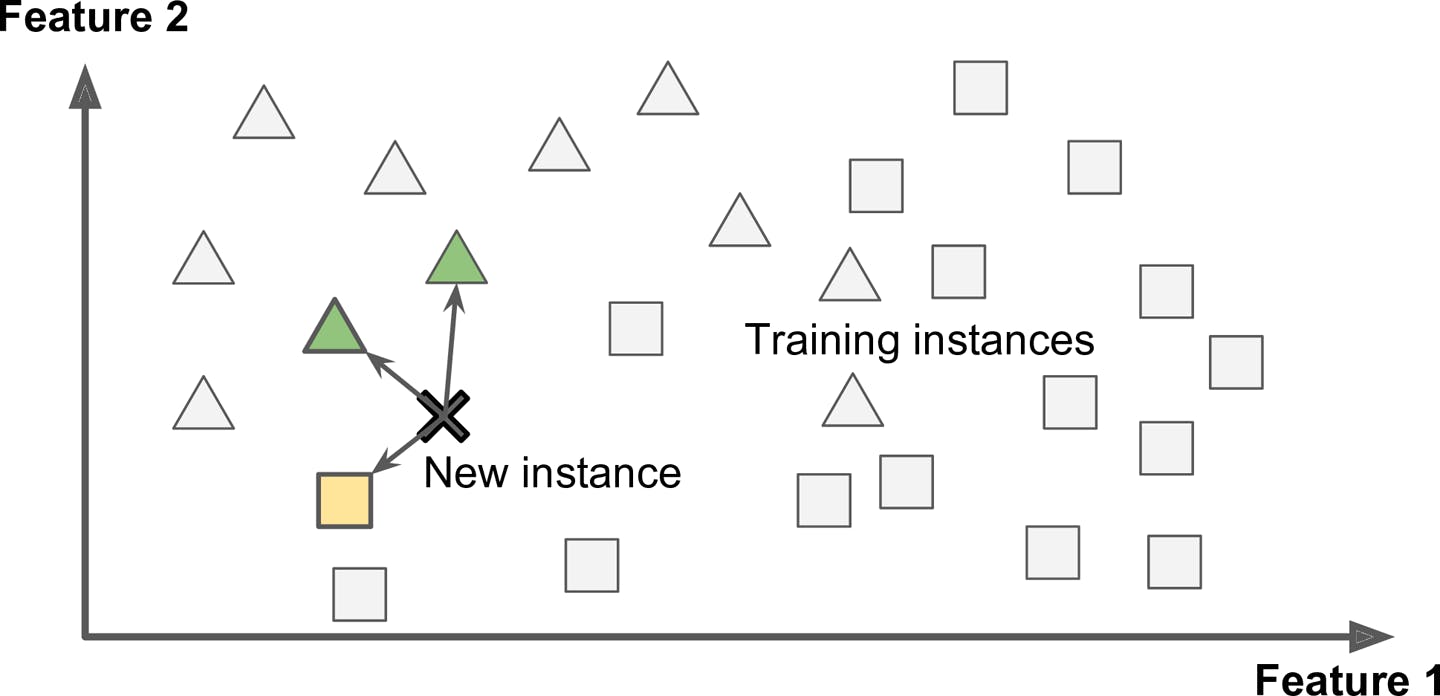 Instance-based learning is the system that learns the examples by heart then generalizes to new cases by using a similarity measure to compare them to the learned examples. In the above example, the new instance would be classified as a triangle because the majority of the most similar instances belong to that class.
Instance-based learning is the system that learns the examples by heart then generalizes to new cases by using a similarity measure to compare them to the learned examples. In the above example, the new instance would be classified as a triangle because the majority of the most similar instances belong to that class.
Model-Based Learning
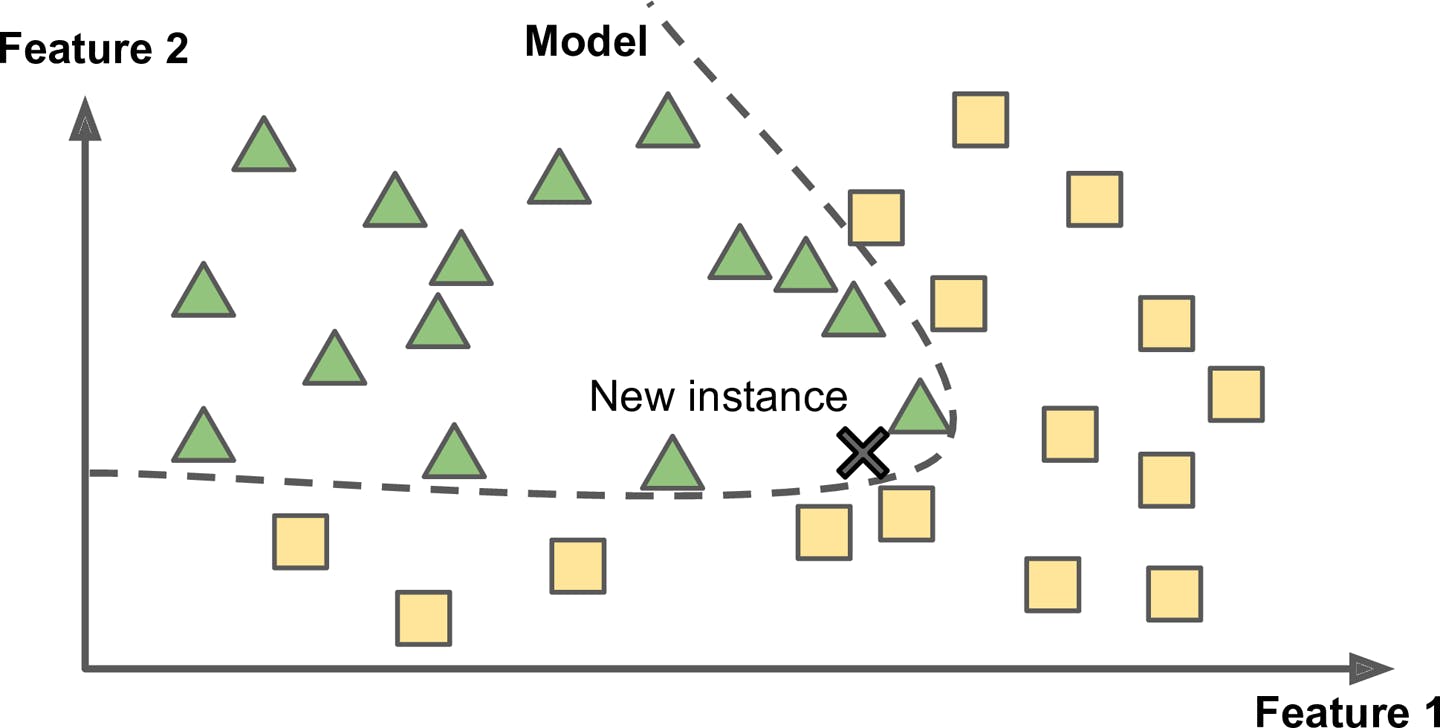
Typical Steps to be followed when performing Model-Based Learning:
- Study the Data
- Select the Model
- Train the Model on the Training Data
- Finally, you apply the model to make predictions on new cases.
Main Challenges of Machine Learning
Insufficient Quantity of Training Data: It takes a lot of data for most Machine Learning algorithms to work properly. Even for very simple problems you typically need thousands of examples, and for complex problems such as image or speech recognition, you may need millions of examples.
Nonrepresentative Training Data: When you are training your data, It is crucial to use a training set that is representative of the cases you want to generalize to. If the sample is too small, you will have sampling noise, but even very large samples can be nonrepresentative of the sampling method is flawed. This is called sampling bias.
Poor Quality Data:If your training data is full of errors, outliers, and noise, it will make it harder for the system to detect the underlying patterns, so your system is less likely to perform well.
Irrelevant Features:As the saying goes garbage in, garbage out. Your system will only be capable of learning if the training data contains enough relevant features and not too many irrelevant ones. A critical part of the success of a Machine Learning project is coming up with a good set of features to train on. This process is called feature engineering.
- Overfitting the Training Data : Overfitting happens when the model is too complex relative to the amount and noisiness of the training data. Suppose Say you are visiting a new city and someone rips you off. You might be tempted to say that everyone in this city is thieves. Overgeneralizing is something that we humans do all too often, and unfortunately, machines can fall into the same trap if we are not careful. In Machine Learning this is called overfitting.
Underfitting the Training Data : Underfitting happens when your model is too simple to learn the underlying structure of the data.
---ThE EnD---
Thank you ❤️ for reading this article, if you like 👍🏽 this article please like/share this article as this will boost me to come up with more articles like this.
Last but not least, here is your quote for the day.
When something is important enough, you do it even if the odds are not in your favor. -- Elon Musk