

Photo by h heyerlein on Unsplash
The Fundamentals of Machine Learning - Part 2
Fundamentals don't change 🤓


 Hello there...This is the Part 2 of The Fundamentals of Machine Learning Series. In this blog, we will be covering the Types of Machine Learning systems.
Hello there...This is the Part 2 of The Fundamentals of Machine Learning Series. In this blog, we will be covering the Types of Machine Learning systems.
Machine Learning Systems can be broadly categorized based on the following criteria:
1) Whether or not they are trained with human supervision(supervised, unsupervised, semisupervised, and Reinforcement Learning)
2) Whether or not they can learn incrementally on the fly(Online Learning Vs Batch Learning)
3) Whether they work by simply comparing new data to known points, or instead by detecting patterns in the training data and building predictive models (Instance-based Vs Model-Based Learning)
Let's look at each case a bit more closely.
Supervised Learning
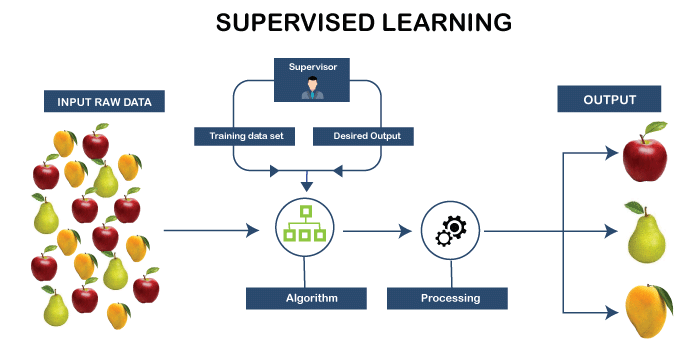 In Supervised Learning, the training set you feed to the algorithm includes desired solutions, called labels.
In Supervised Learning, the training set you feed to the algorithm includes desired solutions, called labels.
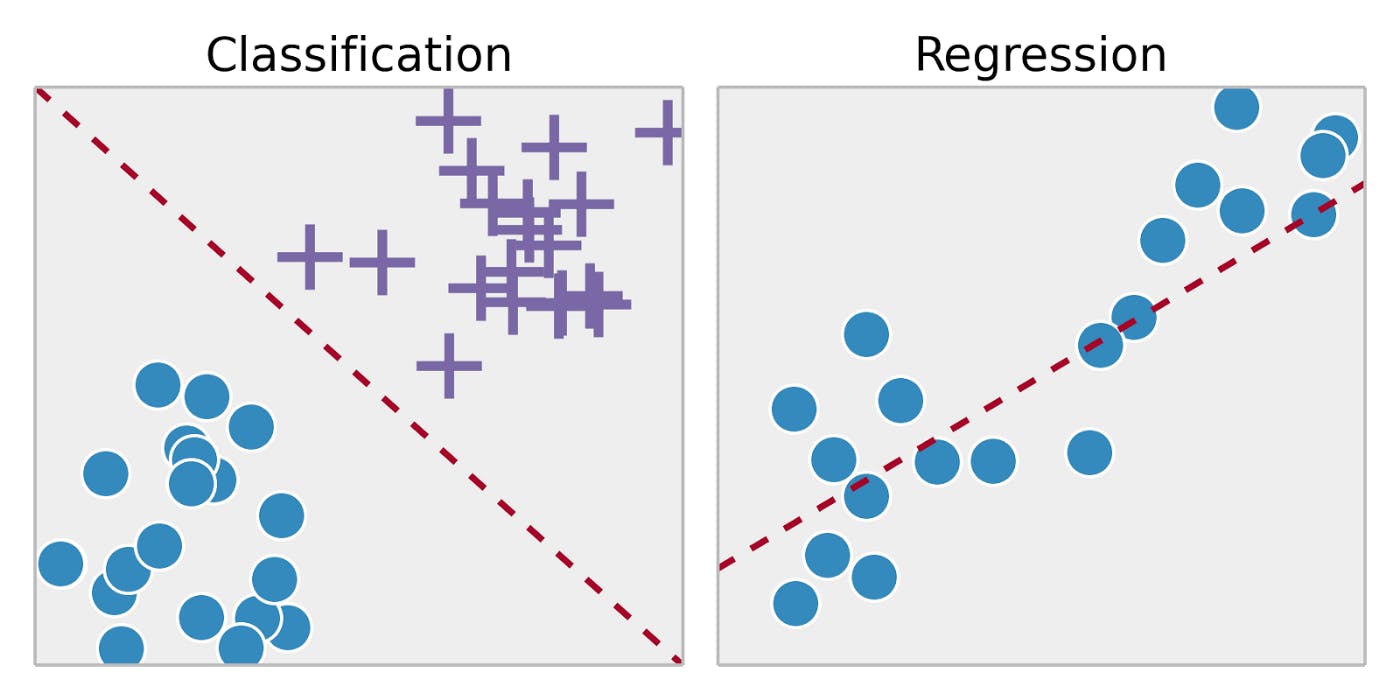
The Spam filter is a good example of this: it is trained with many example emails along with their class(spam or ham), and it must learn how to classify new emails. This sort of task is called Classification.
Another typical task is to predict a target numeric value, such as the price of a car, given a set of features(mileage, age, brand) called predictors. This sort of task is called Regression.
 Here are some important supervised learning algorithms:
Here are some important supervised learning algorithms:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural Networks
Unsupervised Learning
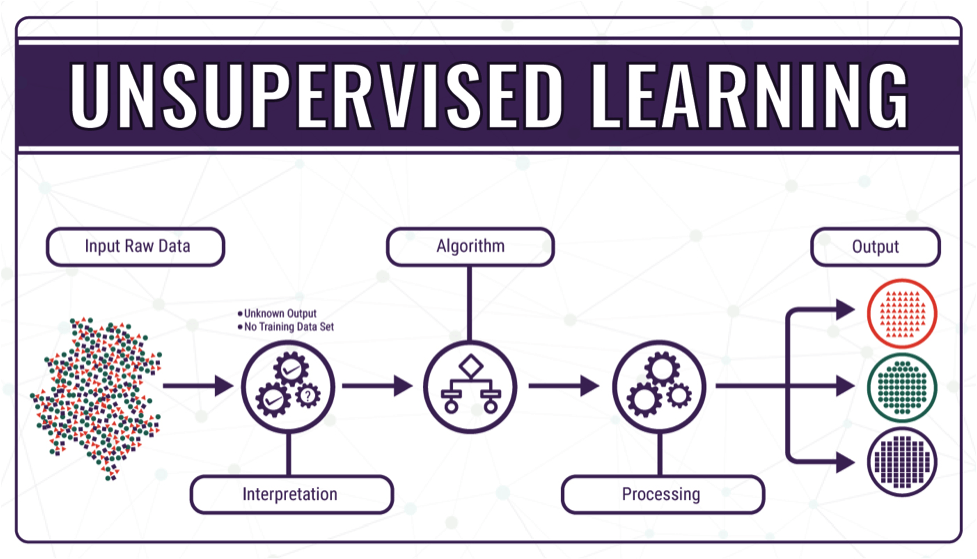 In Unsupervised Learning, the training set you feed to the algorithm Does not include labels. The system tries to learn without a teacher.
In Unsupervised Learning, the training set you feed to the algorithm Does not include labels. The system tries to learn without a teacher.
Here are some important Unsupervised learning algorithms:
- Clustering
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
Anomaly Detection and Novelty Detection
- One-class SVM
- Isolation Forest
Visualization and dimensionality reduction
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally Linear Embedding (LLE)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
Association rule Learning
- Apriori
- Eclat
For example, say you have a lot of data about your blog’s visitors. You may want to run a clustering algorithm to try to detect groups of similar visitors.
Visualization algorithms are the type of unsupervised learning algorithms where you feed them a lot of complex and unlabeled data, and they output a 2D or 3D representation of your data that can easily be plotted.
Anomaly detection aims to detect unusual instances that look different from all instances in the training set. where novelty detection aims to detect new instances that look different from all instances in the training set.
Suppose you own a supermarket. Running an association rule on your sales logs may reveal that people who purchase barbecue sauce and potato chips also tend to buy steak. Thus, you may want to place these items close to one another. This is Association Rule Learning.
Semisupervised Learning
Since labeling data is usually time-consuming and costly, you will often have plenty of unlabeled instances and few labeled instances. Some algorithms can deal with data that’s partially labeled. This is called semisupervised learning. Semisupervised Learning is sometimes combined with Supervised learning and Unsupervised learning.
Reinforcement Learning
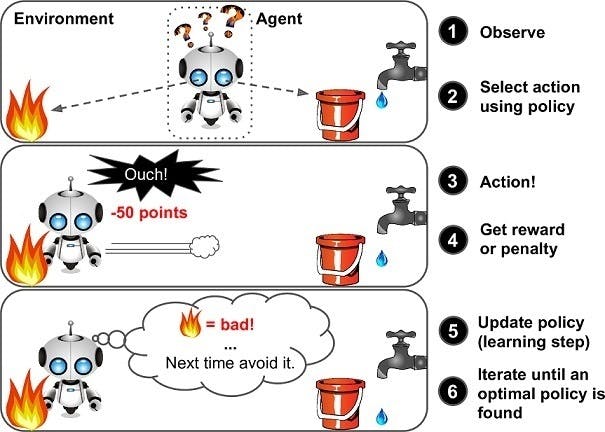 The learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards in return (or penalties in the form of negative rewards).It must then learn by itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when it is in a given situation.
The learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards in return (or penalties in the form of negative rewards).It must then learn by itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when it is in a given situation.
DeepMind’s AlphaGo program is also a good example of Reinforcement Learning.
Batch Learning
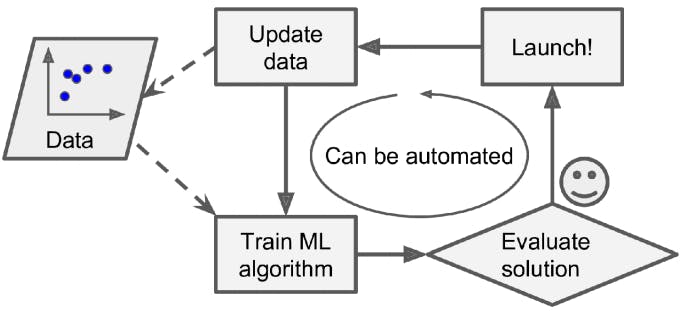 In batch learning, the system is incapable of learning incrementally: it must be trained using all the available data. This will generally take a lot of time and computing resources, so it is typically done offline. First, the system is trained, and then it is launched into production and runs without learning anymore; it just applies what it has learned. This is called offline learning. If you want a batch learning system to know about new data (such as a new type of spam), you need to train a new version of the system from scratch on the full dataset (not just the new data, but also the old data), then stop the old system and replace it with the new one.
In batch learning, the system is incapable of learning incrementally: it must be trained using all the available data. This will generally take a lot of time and computing resources, so it is typically done offline. First, the system is trained, and then it is launched into production and runs without learning anymore; it just applies what it has learned. This is called offline learning. If you want a batch learning system to know about new data (such as a new type of spam), you need to train a new version of the system from scratch on the full dataset (not just the new data, but also the old data), then stop the old system and replace it with the new one.
Online Learning
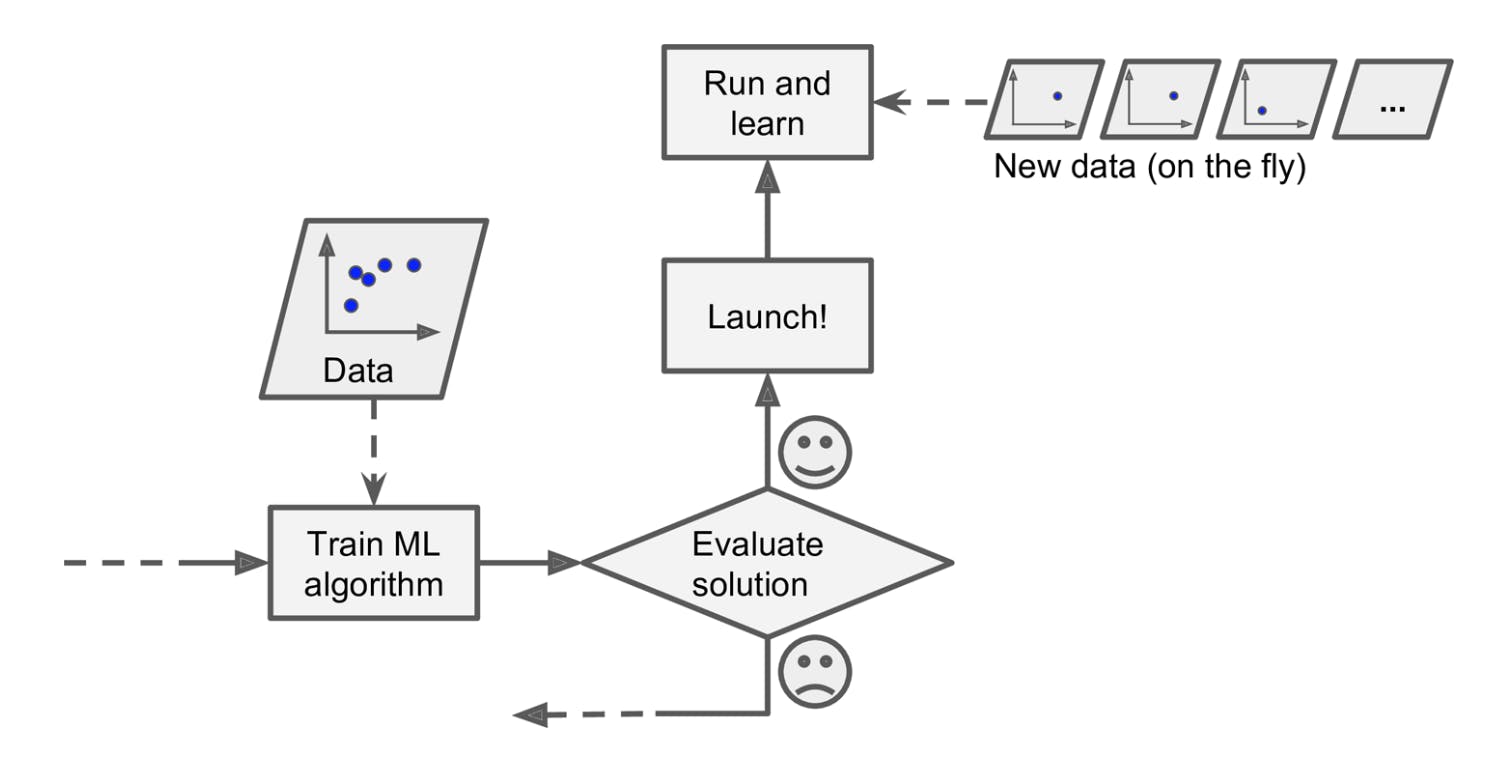 In online learning, you train the system incrementally by feeding it data instances sequentially, either individually or in small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives.
In online learning, you train the system incrementally by feeding it data instances sequentially, either individually or in small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives.
One important parameter of online learning systems is how fast they should adapt to changing data: this is called the learning rate. If you set a high learning rate, then your system will rapidly adapt to new data, but it will also tend to quickly forget the old data (you don’t want a spam filter to flag only the latest kinds of spam it was shown). Conversely, if you set a low learning rate, the system will have more inertia; that is, it will learn more slowly, but it will also be less sensitive to noise in the new data or to sequences of nonrepresentative data points (outliers).
The End. In Part 3 we will cover Instance-Based learning and Model-Based Learning and we will also discuss what are the main challenges in Machine Learning.
- Leaving you with a quote by Steve Jobs
Learn Continually - there is always " One More thing to learn "